随着人工智能与大数据技术的飞速发展,知识图谱作为连接海量异构数据、构建机器认知能力的核心技术,已广泛应用于智能搜索、推荐系统、金融风控、智慧医疗等领域。构建与维护一个大规模、高质量的知识图谱,其背后数据存储系统的设计与选型至关重要。本文将聚焦于大规模知识图谱的数据处理流程与存储支持服务,解析其中的核心挑战与实践方案。
一、 大规模知识图谱数据的特点与存储挑战
大规模知识图谱数据通常具有以下特点:
- 数据规模庞大(Volume):涉及数十亿甚至万亿级别的实体与关系。
- 结构复杂多样(Variety):包含结构化的RDF三元组、半结构化的JSON/XML属性,以及非结构化的文本描述、图像等。
- 高度关联性(Relation):实体之间通过多种关系深度连接,形成复杂的网络拓扑。
- 动态演变(Velocity):知识需要持续更新,支持增量和实时数据的接入。
这些特点对存储系统提出了严峻挑战:如何高效存储海量三元组、如何支持复杂的图查询(如多跳查询、路径查询)、如何保证高并发读写性能、以及如何实现水平扩展。
二、 数据处理流程:从原始数据到知识存储
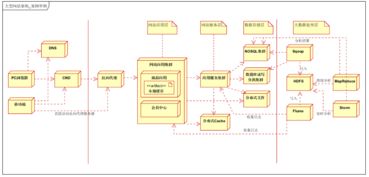
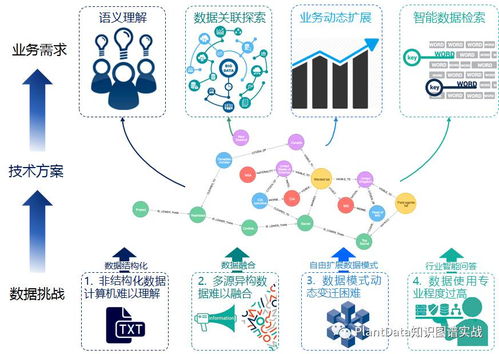
大规模知识图谱的构建始于数据处理,这是一个多阶段的流水线:
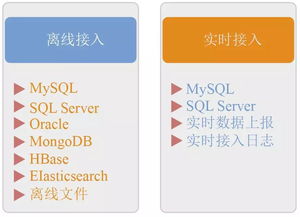
- 数据采集与接入:从异构数据源(数据库、文档、API、网页)收集原始数据。存储支持服务需提供灵活的数据接入接口(如Kafka消息队列),缓冲高速流入的数据。
- 知识抽取与融合:通过自然语言处理(NLP)技术从非结构化文本中抽取实体、关系、属性,并与现有知识进行对齐、消歧、融合。此阶段产生结构化的RDF三元组或属性图数据。
- 数据清洗与质量管控:对抽取的知识进行一致性校验、冲突解决与补全。存储系统在此阶段可提供版本管理或事务支持,确保数据质量。
- 存储建模与导入:将清洗后的数据转换为目标存储模型(如属性图模型或RDF模型),并通过批量导入工具高效载入存储引擎。
三、 存储支持服务的核心架构与选型
针对上述挑战,现代知识图谱存储支持服务通常采用分层或混合架构。
1. 核心存储引擎选型
- 原生图数据库(如Neo4j, JanusGraph, Nebula Graph):以“图优先”方式存储,将关系作为一等公民,在深度关联查询(如最短路径、社区发现)上性能卓越。适用于关系复杂、查询模式多变的场景。
- RDF三元组存储(如Apache Jena Fuseki, Virtuoso):专门为RDF标准设计,支持SPARQL查询,语义推理能力强。常见于需要严格遵循语义网标准的领域。
- 分布式键值/列式存储(如HBase, Cassandra)与图计算层结合:利用其强大的水平扩展能力存储底层数据,通过上层图计算引擎(如Apache TinkerPop)提供图查询接口。适合数据量极其庞大、需要线性扩展的场景。
2. 混合存储架构实践
单一存储引擎往往难以满足所有需求,因此混合架构成为趋势:
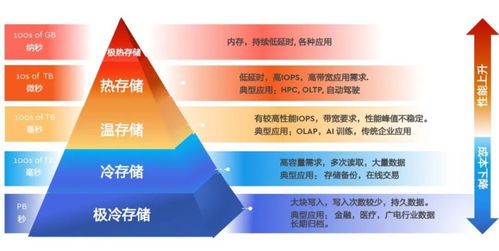
- “热-温-冷”数据分层存储:将高频访问的“热”数据(如核心实体关系)存放在内存或SSD图数据库中,保证低延迟查询;将“温”数据(历史关系、详细属性)存放在分布式NoSQL数据库中;将归档的“冷”数据存放在对象存储(如S3)中。通过统一查询层对应用透明。
- 图数据库与搜索引擎(如Elasticsearch)结合:图数据库处理关联查询,搜索引擎处理全文检索和复杂属性过滤,二者通过同步机制保持数据一致,优势互补。
- OLTP与OLAP分离:在线事务处理(OLTP)图数据库负责实时增删改查,而将数据定期同步到数据仓库或图计算平台(如Spark GraphX)进行离线分析、挖掘和批量计算。
四、 实战考量与优化策略
- 数据建模:根据查询模式设计图模型(如邻接表、属性图),合理使用索引(如对实体类型、常用属性建立索引),避免超级节点(高度数节点)的出现。
- 分区与分片:对于分布式存储,需设计有效的图分区策略(如基于边切割或基于节点哈希),以最小化跨分区查询,提升性能。
- 缓存策略:利用Redis等缓存高频查询结果或热门子图,显著减少后端存储压力。
- 一致性、可用性与扩展性权衡:根据业务需求在强一致性与最终一致性之间做出选择,设计平滑的集群扩容方案。
- 监控与运维:建立完善的监控体系,跟踪存储性能指标(如查询延迟、吞吐量)、数据增长趋势,实现自动化备份与恢复。
五、 未来展望
大规模知识图谱存储将朝着更智能、更融合的方向发展:云原生图数据库服务(Graph DBaaS)将简化运维;存储与计算一体化架构将进一步提升实时分析能力;结合新型硬件(如PMem、GPU)的图加速技术也将成为研究热点。
###
构建大规模知识图谱的存储系统是一项复杂的系统工程,没有“银弹”。成功的实践源于对业务场景、数据特性与查询模式的深刻理解,以及对不同存储技术栈的巧妙组合与优化。通过构建健壮的数据处理流水线与灵活高效的存储支持服务,方能释放出海量知识背后的巨大价值,为上层智能应用奠定坚实的数据基石。