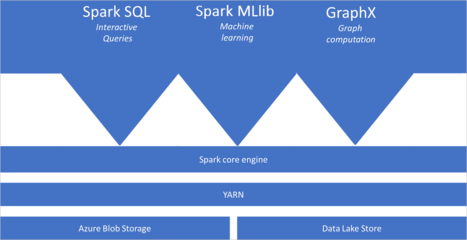
Azure Synapse Analytics 中的 Apache Spark 是一种快速、大规模并行处理的数据分析引擎,它作为 Azure Synapse Analytics 的核心组件,提供了强大的数据处理和存储支持服务。
Apache Spark 在 Azure Synapse Analytics 中的核心价值体现在多个方面。在数据处理方面,它支持批处理和流处理,能够处理从 GB 到 PB 级别的海量数据。用户可以使用 Scala、Python、SQL 和 .NET 等多种编程语言进行数据开发,通过 Notebook 界面进行交互式数据分析。
在存储支持方面,Azure Synapse Analytics 的 Spark 池与 Azure Data Lake Storage Gen2 深度集成,可以实现统一的数据存储和访问。同时,它还支持多种数据格式,包括 Parquet、JSON、CSV 等,并能与 Azure SQL Database、Cosmos DB 等数据服务无缝连接。
Spark 在 Azure Synapse Analytics 中的优势包括:
- 无服务器 Spark 池,无需管理基础设施
- 内置连接器支持多种数据源
- 与 Synapse SQL 引擎的深度集成
- 自动优化和性能调优
- 企业级安全性和合规性
通过使用 Azure Synapse Analytics 中的 Apache Spark,企业可以构建端到端的数据分析管道,实现数据湖和数据仓库的统一管理,大幅提升数据处理效率和数据分析能力。